By
By
What is a Topic Model?
Topic Modeling is one of my favorite NLP techniques. It is a technique for discovering topics in a large collection of documents. It allows you to take unstructured text and bring structure into topics, which are collections of related words. A subject matter expert can then interpret these to give them additional meaning.
We scraped the data we'll be using for this analysis from the official Tesla User Forums. It's a collection of about 55,000 entries consisting of Tesla owners asking questions about their cars and the community providing answers. User forums are a great place to mine for customer feedback and understand areas of interest. We'll approach this as a Product Manager looking for areas to investigate.
Latent Dirichlet Allocation (LDA)
The specific methodology used in this analysis is Latent Dirichlet Allocation (LDA), a probabilistic model for generating groups of words associated with n-topics. In LDA, the algorithm looks at documents as a mixture of topics. The topics are a mixture of words, and the algorithm calculates the probability of each word associated with a topic. LDA is potentially the most common method for building topic models in NLP.
This post will not get into the details of LDA, but we'll be using the Gensim library to perform the analysis. If you would like to learn more about LDA, check out the paper by Blei, Ng, & Jordan (2003).
Two terms you will want to understand when evaluating LDA models are:
- Perplexity: Lower the perplexity better the model.
- Coherence: Higher the topic coherence, the topic is more human interpretable.
Text Cleaning and Prep
We must clean the text used for Topic Modeling before analysis. The objective is to find as munch commonality amongst words, and therefore you want to avoid issues like Run, run, and running being interpreted as a different word. I've covered Text Cleaning in this series already. We applied the methods from this article directly to the data. I opted to use Lemmatization over Stemming since words tend to be more interpretable when brought to their root or lemma versus being chopped off with stemming.
We'll start by importing the necessary libraries and loading our data.
import numpy as np
import pandas as pd
from collections import defaultdict
from gensim import corpora, models
from gensim.models import Phrases
from gensim.models import CoherenceModel
from gensim.models.ldamodel import LdaModel
import pyLDAvis
import pyLDAvis.gensim_models as gensimvis
import matplotlib.pyplot as plt
from matplotlib.lines import Line2D
import seaborn as sns
%matplotlib inline
df = pd.read_pickle('tesla_clean.pkl')
We first need to turn our column from the Data Frame into a giant list, a simple task that we can do with one line.
documents = df['Discussion_Clean'].to_list()After we have our list of documents, we can create a list of stop words and remove them and tokenize each document. Tokenizing is the process of breaking the string up into individual words.
Note: I recommend building your stop word list. You can iterate over your model and remove words that add little to no value to your topics. The words you might wish to remove probably are not common stop words but are not helping you interpret the results. Towards the end of my stop list, you can see words like troll and fish which are not helpful.
stoplist = ['the', 'a', 'an', 'of', 'and', 'or', 'in', 'for', 'to', 'at', 'by', 'from', 'with', 'on', 'as', 'but', 'is', 'are', 'was', 'were', 'be', 'been', 'am', 'i', 'me', 'my', 'we', 'our', 'you', 'fish', 'troll', 'ha', 'bye', 'ok', 'okay', 'andy', 'idiot']
# remove common words and tokenize
texts = [[word for word in document.split() if word not in stoplist]
for document in documents]
Next, we can remove words that infrequently occur; in this case, only words that only appear once in the corpus. We can adjust this number to your needs.
# remove words that appear only once
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
texts = [[token for token in text if frequency[token] > 1]
for text in texts]
Another treatment you can add is n-grams to your documents. You can experiment with this on your own and see how it affects your results.
# Add bigrams to docs (only ones that appear 20 times or more).
bigram = Phrases(texts, min_count=20)
for idx in range(len(texts)):
for token in bigram[texts[idx]]:
if '_' in token:
# Token is a bigram, add to document.
texts[idx].append(token)
Next we create our dictionary and corpus. The corpus is a list of documents, and the dictionary lists unique words. Note the powerful function to remove words that are extremes. You can hone in on more meaningful topics depending on your documents by adjusting these values.
# Create the dictionary
dictionary = corpora.Dictionary(texts)
# Filter out words that occur less than X documents,
# or more than X% of the documents.
dictionary.filter_extremes(no_below=50, no_above=0.5)
# Create the corpus. This is a Term Frequency
# or Bag of Words representation.
corpus = [dictionary.doc2bow(text) for text in texts]
print(f'Number of unique tokens: {len(dictionary)}')
print(f'Number of documents: {len(corpus)}')
Number of unique tokens: 2462
Number of documents: 54335
Training the Topic Model
Next, we need to train the topic model. Training in this context is somewhat akin to hyperparameter tuning in a Machine Learning model. We will iterate through different parameters until the model converges across all (or almost all) of our documents. We need to turn logging into DEBUG mode to do this, and we can do this via the following code.
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.DEBUG)
Next, we can set parameters and attempt multiple passes until we get the results we want.
NUM_TOPICS = 10
chunksize = 2000
passes = 6
iterations = 100
eval_every = 1
temp = dictionary[0]
id2word = dictionary.id2token
model = LdaModel(
corpus=corpus,
id2word=id2word,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
num_topics=NUM_TOPICS,
passes=passes,
eval_every=eval_every
)After running this, open up the log (if you're using VS Code, you should be able to open it in a new tab). Next, search for converged and look for a line like the following. Adjust the iterations and passes values until you see all the documents converged. After some playing with my model, I ended up with the following results.
2022-01-01 : DEBUG : 1998/2000 documents converged within 100 iterations
2022-01-01 : DEBUG : 335/335 documents converged within 100 iterations
With these settings, you can now choose the best number of topics. The Gensim documentation 2 describes this process as well.
Choosing the Best Number of Topics
To choose the best number of topics, we can calculate the coherence value for different topic-number settings and determine which has the greatest value. The below function simplifies this and can be a bit of a time-consuming process. Try to iterate through and get the best results. I wouldn't recommend running 100 processes stepping by 1 to begin.
def compute_coherence_values(dictionary, corpus, texts,
cohere, limit, start=2, step=2):
coherence_values = []
for num_topics in range(start, limit, step):
model = LdaModel(corpus=corpus,
id2word=dictionary,
num_topics=num_topics,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
passes=passes,
eval_every=eval_every,
random_state=42,)
coherencemodel = CoherenceModel(model=model,
texts=texts,
dictionary=dictionary,
coherence=cohere)
coherence_values.append(coherencemodel.get_coherence())
return coherence_values
Next, we'll create some parameters for stepping through the range of topics we want to test. Some corpus might have hundreds of topics; smaller ones will have few. You can play with these values to see how yours change. I started with stepping to 100 by 5originally to narrow down the window and then stepped by 2 when finishing. We will also use these variables in the plot below, which is why they're separated.
limit=50
start=2
step=2
Let's run the above function calculating the coherence value for each number of topics. The result of the function returns a list of values.
coherence_values = compute_coherence_values(dictionary=dictionary,
corpus=corpus,
texts=texts,
cohere='c_v',
start=start,
limit=limit,
step=step)
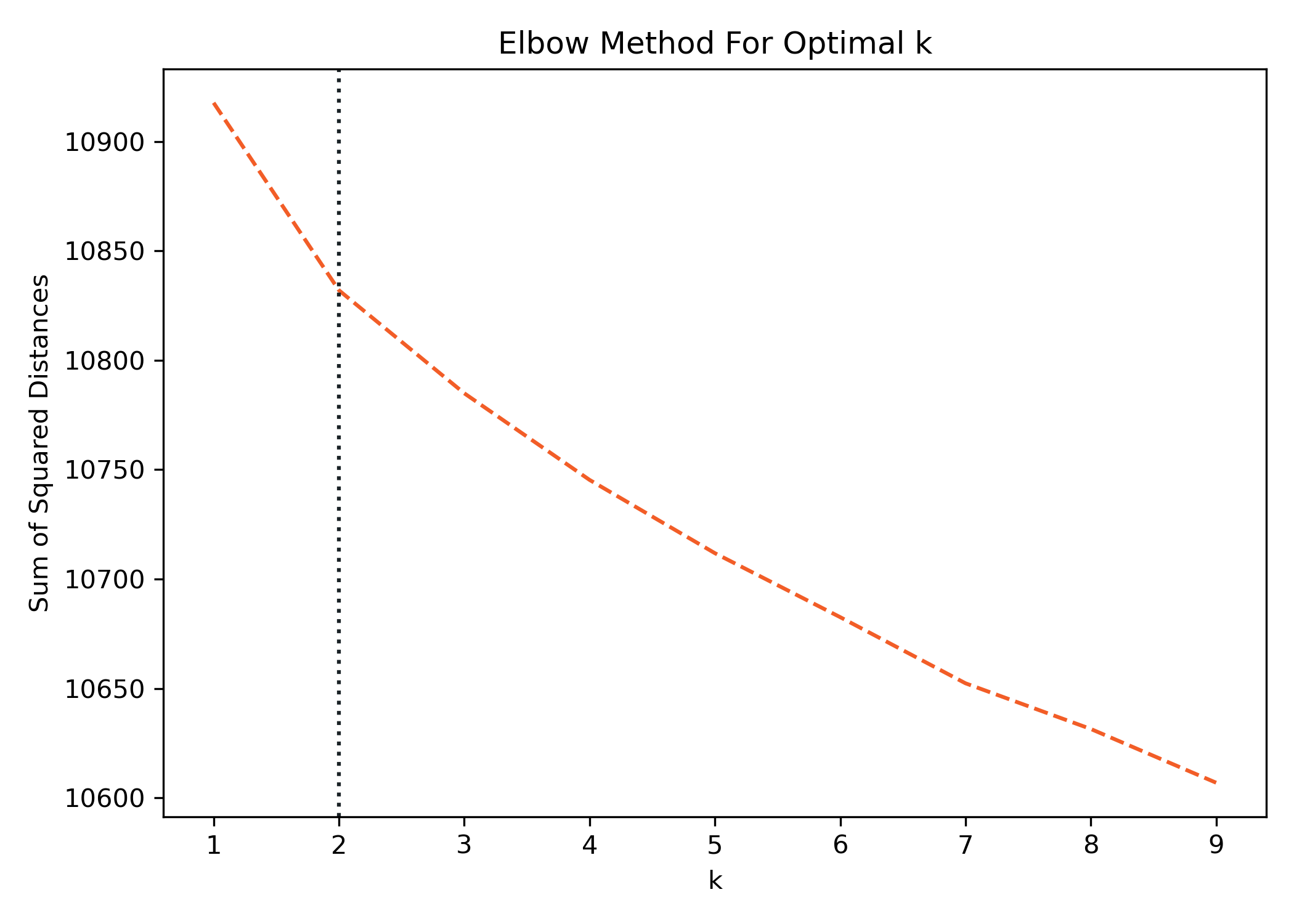
We can now easily plot these values and calculate the Max value. I've plotted a vertical line to help visualize it easier.
plt.figure(figsize=(8,5))
# Create a custom x-axis
x = range(start, limit, step)
# Build the line plot
ax = sns.lineplot(x=x, y=coherence_values, color='#238C8C')
# Set titles and labels
plt.title("Best Number of Topics for LDA Model")
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.xlim(start, limit)
plt.xticks(range(2, limit, step))
# Add a vertical line to show the optimum number of topics
plt.axvline(x[np.argmax(coherence_values)],
color='#F26457', linestyle='--')
# Draw a custom legend
legend_elements = [Line2D([0], [0], color='#238C8C',
ls='-', label='Coherence Value (c_v)'),
Line2D([0], [1], color='#F26457',
ls='--', label='Optimal Number of Topics')]
ax.legend(handles=legend_elements, loc='upper right')
We can see here that the Coherence Value peeks at 8. Remember above we said:
Higher the topic coherence, the topic is more human interpretable.
While this is great for guidance, you must still interpret the results and determine if they make sense. We'll utilize 8 topics as our final and visualize the results.
Final Run and Visualiztion of the Results
Finally, we can run our trained and tuned model and visualize our results!
temp = dictionary[0]
id2word = dictionary.id2token
model = LdaModel(
corpus=corpus,
id2word=id2word,
chunksize=2000,
alpha='auto',
eta='auto',
iterations=100,
num_topics=8,
passes=8,
eval_every=None)
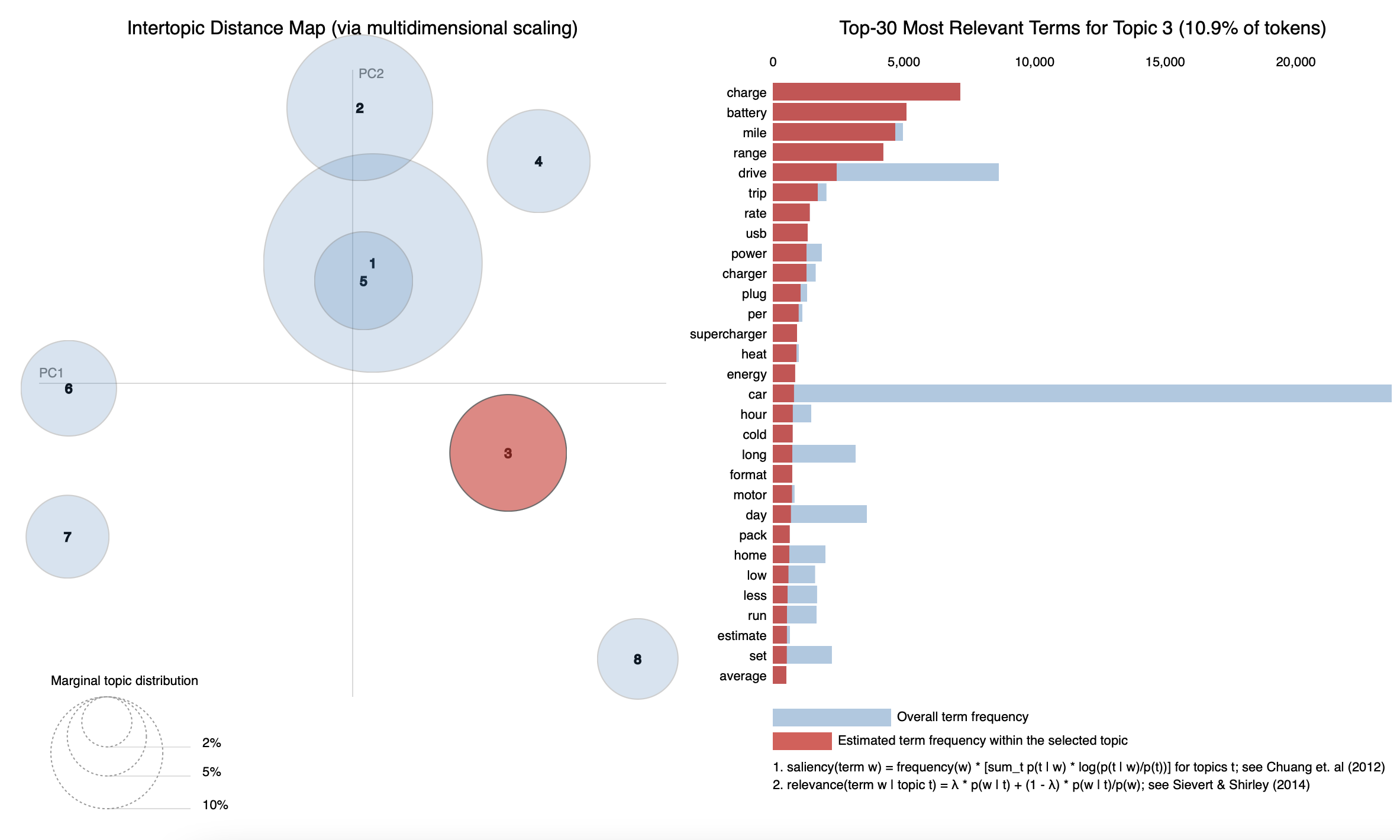
Next, let's visualize the results. We'll use the pyLDAvis package to visualize the results.
pyLDAvis.enable_notebook()
# feed the LDA model into the pyLDAvis instance
lda_viz = gensimvis.prepare(model, corpus, dictionary, sort_topics=True)
pyLDAvis.display(lda_viz)
Conclusion
Topic Models are an incredibly powerful tool for interpreting unstructured text. Topic Modeling can be used on various sources such as social media, product reviews, customer support tickets, and more. As a former Product Manager, I've used topic modeling to inform roadmap decisions on where to invest resources and prioritize. Best of luck on your journey utilizing them!